- Operating Systems Course
- Operating System Tutorial
- History of Operating System
- Personal Computer OS
- OS Processes
- OS Process Model
- OS Process Creation
- OS Deadlocks
- OS Deadlock Recovery
- OS Two-Phase Locking
- OS Memory Management
- OS Mono programming
- OS Shared Pages
- Operating System Input/Output
- OS Input/Output Devices
- OS Input/Output Software Layers
- OS Disk Hardware
- OS Files
- OS File Naming
- OS File Types
- OS Hierarchical Directory System
- OS Directory Operations
- OS File Operations
- Multimedia Operating System
- OS Multiprocessors
- Operating System Security
- OS User Authentication
- OS Trap Doors
- OS Viruses
Memory Management in Operating System
The most important resource is memory, which must be carefully managed.
Every programmer, and even the average computer programmer or user, desires an infinitely large and fast memory. And the memory is also non-volatile memory, meaning a memory that doesn't lose its content when the power supply stops.
The memory hierarchy in the operating system is managed by the memory manager.
The work of the memory manager is to keep track of which parts of the memory are in use and which parts are not in use, then allocate the memory to processes whenever they need it and, when their work is done, de-allocate that part of the memory.
There is another use for a memory manager, which is to manage the swapping between main memory and disc when main memory is too small to hold all the processes.
Memory management systems are basically divided into the following two classes:
- one that moves processes back and forth between main memory and disc during execution.
- And second, that doesn't
Today, efficient memory management must be performed because software is growing even faster than memory.
You will learn all about memory management in detail, divided into the following topics:
- Mono programming
- Multiprogramming
- Relocation and Protection
- Bitmaps
- Linked Lists
- Virtual Memory
- Page Replacement Algorithms
- Local Vs. Global Allocation Policies
- Load Control
- Page Size
- Separate Instruction and Data Spaces
- Shared Pages
- Cleaning Policies
- Virtual Memory Interface
Except for "Mono programming" and "shared pages," which are covered in the following two posts, all of the above topics are covered in this post.
Memory Management: Multiprogramming
Almost all computer systems today allow multiple processes to run concurrently. When multiple processes run at the same time, it means that while one is waiting for input or output to complete, another can use the central processing unit.
As a result, multiprogramming makes better use of the central processing unit. Both network servers and client machines can now run multiple processes at the same time.
The simplest method for multiprogramming is to divide memory into n partitions of varying sizes. Multiprogramming allows processes to use the central processing unit when necessary. When multiprogramming is used, the utilisation of the Central Processing Unit (CPU) can be increased.
Memory Management: Relocation and Protection
Relocation and protection are the two problems introduced by multiprogramming that must be solved.
During loading, relocation doesn't solve the protection problem. A malicious program can always construct a new instruction and jump to it. Because programs in this system use absolute memory addresses rather than addresses relative to a register.
There is no way to prevent a program from constructing instructions that read or write words in memory.
In multi-user computer systems, it's totally undesirable to let the processes read or write memory that belongs to the other users.
As a result, IBM's solution for simply protecting the 360 was to divide the memory into 2KB blocks and assign each block a 4 bit protection code.
The PSW contained a 4-bit key; here, PSW stands for Program Status Word.
The 360 hardware trapped any attempt by a running process to access the memory, whose protection code was different from the program status word key.
Since only the OS could change the protection codes and protection key, user processes were prevented from interfering with one another or with the OS itself, to equip the machine with two hardware registers (special hardware registers) called the base registers and limit registers, in an alternative solution to both relocation and protection problems.
Whenever a process is scheduled, the base register is loaded with the address of the start of its partition, and the limit register is loaded with the length of the partition.
Every memory address generated automatically has the contents of the base registers added to it before being sent to memory.
Memory Management: Bitmaps
Memory is divided up into allocation units using a bitmap.
Corresponding to each allocation unit is a bit in the bitmap, which is zero (0) if the unit is free and one (1) if the unit is occupied, and vice versa.
The size of the allocation unit is an important design consideration. The larger the bitmap, the smaller the allocation unit.
Because the bitmap size is determined by the memory size and the allocation unit size, it provides an easy way to keep track of memory words in a fixed amount of memory.
Memory Management: Linked Lists
Another method for keeping track of memory is to keep a linked list of allocated memory segments and free memory segments, where a segment is either a process or a gap between two processes.
Several algorithms can be used to allocate memory for a newly created process or an existing process that is being swapped in from disc when processes and holes are kept on a list that is sorted by address. We assume that memory management is aware of how much memory to allocate. Algorithms of various types can be used to accomplish this.
The table below describes the various types of algorithms:
| Algorithm | Description |
|---|---|
| First fit | The memory manager scans the list of segments in the first-fit algorithm until it finds a large enough hole. Except in the statistically unlikely case of an exact fit, the hole is divided into two parts: process and unused memory. This algorithm is fast because it searches as little as possible. |
| Next fit | The next fit algorithm operates similarly to the first fit algorithm, except that it keeps track of its location whenever it finds a suitable hole. |
| Best fit | This algorithm searches the entire list for the smallest suitable hole. Rather than breaking up a large hole that may be required later, this algorithm attempts to find a hole that is close to the actual size required. |
| Worst fit | This algorithm always chooses the largest available hole, ensuring that the hole that is broken off is large enough to be useful. |
| Quick fit | This algorithm keeps separate lists for some of the most commonly requested sizes. |
Memory Management: Virtual Memory
The basic idea behind virtual memory is that the combined size, data, and stack of the program may exceed the amount of physical memory available to it.
The program-generated addresses are referred to as "virtual addresses," and they comprise the "virtual address space."
The operating system keeps the parts of the program that are currently in use in main memory and the rest on disc.
Virtual memory in a multiprogramming system can also work with bits and pieces of multiple programs in memory at the same time. While a program is waiting for a portion of itself to be brought in, it is waiting for input or output and cannot run, so the central processing unit can be given to another process in the same way that it is given to other processes in other multiprogramming systems.
Memory Management: Page Replacement Algorithms
When a page fault occurs, the operating system must choose which page to remove from memory to make room for the page that must be brought in.
If the page to be removed has been modified or edited while in memory, it must be rewritten to disc just to bring the disc copy up to date.
If the page has not been changed or modified, there is no need to rewrite. The disc copy is already up to date in this case.
Simply select a random page for each page fault. When a non-frequently visited page is selected, system performance improves significantly. If a frequently used page is deleted, it must be quickly restored, adding to the overhead.
The page replacement algorithm has received a great deal of attention, both experimentally and theoretically.
The following is a list of the most important page replacement algorithms, along with a brief description of each.
- Optimal Page Replacement Algorithm: The best page replacement algorithm replaces the most recently referenced page among the current pages. However, because there is no way to specify which page will be the last, this algorithm cannot be used in practice; however, this page replacement algorithm can be used as a benchmark against which other page replacement algorithms can be measured.
- Not Recently Used (NRU) Page Replacement Algorithm: The not recently used (NRU) page replacement algorithm classifies pages based on the R and M bit states. A page is chosen at random from the lowest-numbered class.
- First-In First-Out (FIFO) Page Replacement Algorithm: The first-in-first-out (FIFO) page replacement algorithm keeps track of the order in which pages were loaded into memory just by keeping them in a linked list. In the FIFO algorithm, removing the oldest page then becomes trivial, but the page might still be in use, so this page replacement algorithm is not a good choice.
- Second Chance Page Replacement Algorithm: In the second-chance page replacement algorithm, a modification to first-in, first-out checks whether a page is in use before removing it. If it is, then the page is spared. This modification improves the performance of the system.
- Clock Page Replacement Algorithm: The clock page replacement algorithm is basically a different implementation of the second-chance page replacement algorithm. It has the same performance characteristics, but it runs the algorithm faster.
- Not Frequently Used (NFU) Page Replacement Algorithm: The not frequently used (NFU) page replacement algorithm is a crude attempt to approximate the least recently used.
- Working Set Page Replacement Algorithm: The working set page replacement algorithm is expensive to implement but has reasonable performance.
- WSClock Page Replacement Algorithm: The WSClock page replacement algorithm is a variant of the Working Set page replacement algorithm; that is, this page replacement algorithm not only gives good performance but is also efficient to implement.
There are some other page replacement algorithms that are not listed or discussed above. Now I have to tell you that "WSCLock" is one of the best page replacement algorithms.
Memory Management: Local Vs. Global Allocation Policies
The allocation of memory among running processes is a major issue with the paging system. The three processes that comprise the set of runnable processes are depicted in the figure below as A, B, and C.
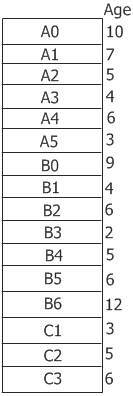
Assume Process A experiences a page fault. The question now is whether the page replacement algorithm should try to find the least recently used page, given that process A currently has only six pages allocated to it, or whether it should consider all pages in memory.
If it only looks at the pages of process A, the page with the lowest age value is A5, resulting in the following situation:
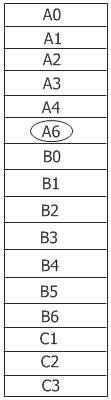
What if the page with the lowest age value is removed regardless of who owns it?
Then page B3 will be selected, resulting in the situation depicted in the figure below:
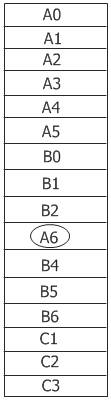
The algorithm in the second figure is referred to as a local page replacement algorithm in this context, while the algorithm in the third figure is referred to as a global page replacement algorithm.
The local algorithm corresponds to allocating a fixed fraction of memory to each process, whereas the global algorithm dynamically allocates page frames among the runnable processes. As a result, the page frame number assigned to each process changes over time.
Global algorithms perform better than local algorithms in general, especially when the size of the working set varies over the course of the process.
Memory Management: Load Control
Even with the best page replacement algorithm and optimal global allocation of page frames to process, the system can become overloaded.
When the combined working sets of all processes exceed the memory capacity, the system will thrash.
One symptom of this situation is that the page fault frequently (PFF) algorithm indicates that some processes require more memory than others. In this case, there is no way to provide additional memory to those processes that require it without interfering with other processes.
To reduce the number of processes competing for memory, simply move some of them to disc and free up all the pages they are holding.
Memory Management: Page Size
The page size is a parameter that can be chosen by OS.
To determine the best page size, several competing factors must be balanced. As a result, there is no overall best solution. Two factors influence the size of a small page.
- A text, data, or stack segment chosen at random will not fill an integral number of pages. On average, half of the final page will be empty, wasting valuable page space (internal fragmentation). With n segments in memory and p bytes of page size, internal fragmentation will waste np/2 bytes.
- Consider a program that has eight sequential phases es o kilobytes4 kilobits. With a page size of 32 kB, the program must always be given 32 kB. And with kBpage sprogramme16 kB, the program only requires 16 kB (4kb each). With a 32kb page size, the program must always be allocated 32kb. And, with a page size of 16kb, the program only requires 16kb. The program requires only 4 KB at any time when the page size is 4 KB or less than 4 KB.
In general, a large page size will result in more unused programs in memory than a small page size.
Memory Management: Separate Instruction and Data Spaces
As shown in the figure given below, most computer systems have a single address space that holds both programs and data.
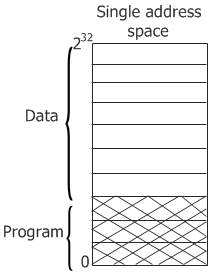
Everything works fine if this address space is large enough. But sometimes it is too small, forcing the programmer to just stand on their heads to fit everything into the address space.
A solution is to have separate address spaces for the program text and the data. There are two distinct areas known as I-space and D-space. Here, each address space runs from 0 to some maximum, typically 232-1. You can see both of them in the figure given below:
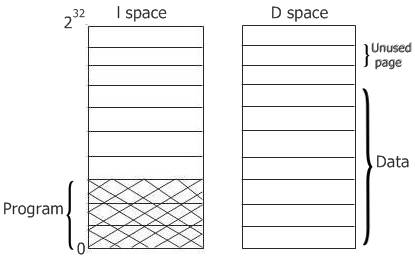
With this design, both address spaces can be pages in the computer system independently of one another.
Memory Management: Cleaning Policies
In an event where the previous page contents are remembered, one of the evicted pages is needed again before it is overwritten. It can be reclaimed just by deleting or removing it from the pool of free page frames.
For your information, keeping the supply of page frames around yields much better performance than using all of the memory and then trying to find a frame at the moment it is needed.
The paging daemon (a background process to ensure a plentiful supply of free page frames) ensures that all the free frames are clean, so they don't need to be written to disc in a hurry whenever they are required.
A two-handed clock is a way to implement this cleaning policy. In this two-handed clock, the front hand is controlled by a paging daemon. Whenever it points to a dirty page, then that page is written back to the disc and the front hand advances. And whenever it points to a clean page, then it is just advanced.
And the back hand is simply used for page replacement, as in the standard clock algorithm. Now, the probability of the back hand hitting a clean page is increased just due to the work of the paging daemon.
Memory Management: Virtual Memory Interface
Prior to this topic, we assumed that virtual memory is transparent to processes and computer programmers, that is, that all they see is a large virtual address space on a computer system with limited physical memory.
That is true for many computer systems; however, in several advanced computer systems, computer programmers have some control over the memory map and can use it in unconventional ways to improve the program's behavior.
A solid reason for giving the computer programmers control over their memory map is just to allow multiple processes to share the same memory.
It is possible for one process to give another process the name of a memory region so that the other process can map it in as well, but only if the computer programmers can name the memory regions.
High bandwidth sharing becomes possible when multiple processes share the same pages, that is, when one process writes into shared memory and another reads from it.
« Previous Topic Next Topic »